import pandas as pd
# Читання файлу CSV
df = pd.read_csv('data.csv')
df.head(5) # Перші 5 рядків
df.info() # Типи даних та чи є пусті значення
df.describe() # Статистика (середнє, мін, макс)Practice Session 15
📊 Базова робота з бібліотеками: Pandas та Matplotlib
Pandas та Matplotlib — це дві найпопулярніші бібліотеки для роботи з даними та їх візуалізації у Python. Pandas дозволяє ефективно обробляти та аналізувати дані у вигляді таблиць, тоді як Matplotlib надає потужні інструменти для створення різноманітних графіків і діаграм. Ми розглянемо основи роботи з цими бібліотеками та застосуємо їх можливості для аналізу та візуалізації даних.
ПопередженняЗауважте!
Для успішного виконання цієї практичної, вам знадобиться зробити Fork репозиторію, а потім клонувати його на свій пристрій. Для того, аби здати практичну, вам потрібно буде надіслати pull request
📌 План заняття:
- Основи роботи з Pandas та великими даними
- Matplotlib та візуалізації даних
- Поєднання Matplotlib + Pandas
📝 Cheat Sheet:
Pandas — робота з таблицями (читання, фільтрація, створення колонок).
Matplotlib — малювання графіків на основі цих таблиць.
🐼 Pandas (База)
1. Завантаження та огляд
2. Вибір та маніпуляція даними
# Вибір однієї колонки
prices = df['Ціна']
# Створення нової колонки (або оновлення існуючої)
df['Знижка'] = df['Ціна'] * 0.5
# Пошук найбільших/найменших значень
top_3 = df.nlargest(3, 'Ціна')
bottom_3 = df.nsmallest(3, 'Ціна')3. Фільтрація (Маски)
# Проста умова
adults = df[df['Вік'] >= 18]
# Складна умова (& = ТА, | = АБО). Умови обов'язково в круглих дужках!
target_audience = df[(df['Вік'] >= 18) & (df['Місто'] == 'Київ')]📊 Matplotlib
1. Основні типи графіків
import matplotlib.pyplot as plt
# Спочатку завжди задаємо розмір графіка (ширина, висота)
plt.figure(figsize=(8, 4))
# Лінійний графік (тренди, час)
plt.plot(df['Місяць'], df['Прибуток'])
# Стовпчаста діаграма (порівняння категорій/ТОПів)
plt.bar(df['Назва_товару'], df['Кількість'])
# Точковий графік (пошук залежності між двома цифрами)
plt.scatter(df['Витрати_на_рекламу'], df['Продажі'])2. Оформлення
plt.title("Головний заголовок")
plt.xlabel("Назва осі X (горизонталь)")
plt.ylabel("Назва осі Y (вертикаль)")
plt.grid(True) # Сітка
# ОБОВ'ЯЗКОВО в кінці, щоб відобразити графік
plt.show() Основи роботи з Pandas та великими даними
👨💻 Live coding 1: Дослідження глобальних проблем
Контекст: Сьогодні ми приміряємо на себе роль дата-аналітиків ВООЗ. Нам надійшов свіжий звіт Global_Mental_Health_Crisis_Index_2026. Наше завдання — завантажити його, подивитися на структуру, а потім знайти європейські країни, де рівень депресії перевищує 5%. Це базова фільтрація, з якої починається будь-який аналіз.
Вхідні дані: Файл Global_Mental_Health_Crisis_Index_2026.csv.
Очікуваний результат: Виведення інформації про датасет та відфільтрована таблиця
🛠 Guided Practice:
Контекст: Робота аналітика полягає не тільки в тому, щоби витягнути дані, а й в тому, що би перевіряти різні твердження та робити певні висновки. Вам потрібно переверіти гіпотезу про те, чи гарантують великі гроші хорошу систему підтримки.
Ваше завдання - знайти багаті країни (ВВП на душу населення більше 40 000 доларів), де загальна оцінка системи ментального здоров’я mh_system_score менша за 5.0 балів.
Створіть нову колонку "lack_of_care_mln", помноживши населення population_millions на відсоток людей, які не отримують лікування treatment_gap_pct / 100. Виведіть результат.
Вхідні дані: Датафрейм з попереднього завдання.
Очікуваний результат: Створення нової колонки, фільтрація за двома умовами, виведення таблиці.
Matplotlib та візуалізації даних
Matplotlib — це найпопулярніша бібліотека для візуалізації даних у Python. Будь-який графік починається з полотна (
figure), на яке ми наносимо дані за допомогою різних функцій (plot,bar,scatterтощо), а потім додаємо оформлення (підписи, заголовки).
1. Лінійний графік (Line Plot)
Ідеально підходить для відображення трендів, змін у часі або послідовностей.
import matplotlib.pyplot as plt
days = ['Пн', 'Вв', 'Ср', 'Чт', 'Пт']
coffee_sales = [45, 50, 42, 60, 85]
plt.figure(figsize=(8, 4)) # figsize=(ширина, висота) в дюймах
plt.plot(days, coffee_sales, color='blue', marker='o', linestyle='--')
plt.title("Тренд продажів кави")
plt.xlabel("Дні тижня")
plt.ylabel("Кількість чашок")
plt.grid(True) # Вмикаємо сітку
plt.show() # Відображаємо результат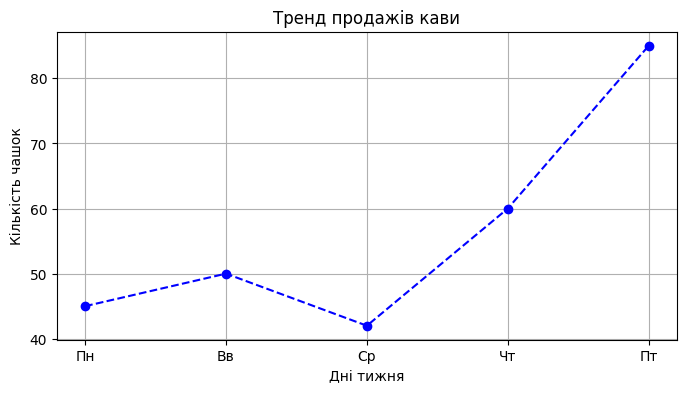
2. Стовпчаста діаграма (Bar Chart)
Використовується для порівняння різних категорій між собою (наприклад, який товар продається краще).
drinks = ['Еспресо', 'Латте', 'Капучино']
popularity = [120, 300, 250]
plt.figure(figsize=(8, 4))
plt.bar(drinks, popularity, color=['#8B4513', '#DEB887', '#D2B48C'])
plt.title("Популярність напоїв")
plt.ylabel("Кількість замовлень")
plt.show()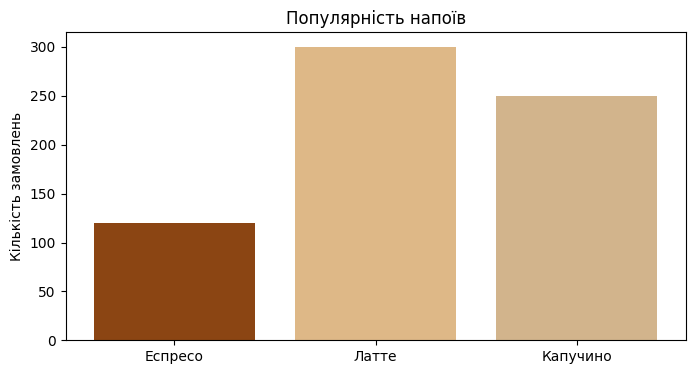
3. Точковий графік (Scatter Plot)
Допомагає шукати залежності (кореляції) між двома числовими показниками. Чи впливає один параметр на інший?
hours_studied = [1, 2, 3, 4, 5, 6]
exam_scores = [40, 50, 65, 70, 85, 90]
plt.figure(figsize=(8, 4))
plt.scatter(hours_studied, exam_scores, color='red', s=150, alpha=0.7) #
plt.title("Залежність балів від часу підготовки")
plt.xlabel("Години підготовки")
plt.ylabel("Бал за іспит")
plt.show()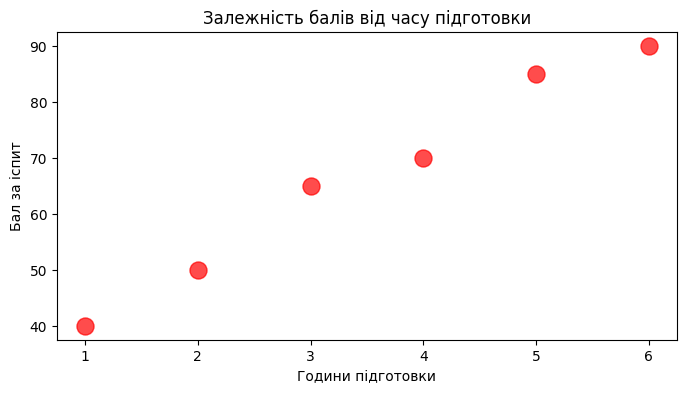
Поєднання Matplotlib + Pandas
👨💻 Live Coding 2:
Контекст: Окрім аналізу даних, їх також потрібно правильно презентувати. На цю тему навіть пишуть цілі книжки! Проте ми спробуємо розібратися з базовими принципами візуалізації даних на прикладі нашого датасету.
Давайте перевіримо, чи завжди депресія йде пліч-о-пліч з тривожністю. Візьмемо ТОП-5 країн за рівнем депресії і побудуємо для них одразу два лінійні графіки на одному полотні.
Вхідні дані: Датафрейм з попереднього завдання.
Очікуваний результат: Горизонтальна діаграма з лінією тренду
🛠 Guided Practice:
Контекст: Перед вами, вже не вперше, постає задача перевірити тевердження. Проте тепер, дані треба підтвердити візуалізацією. Чи правда, що чим більше часу люди проводять у соцмережах, тим гірший у них стан ментального здоров’я?
Для того щоб підтвердити або спростувати, вам потрібно побудувати точковий графік (scatter), де по осі X буде середній час у соцмережах (social_media_hours_daily), а по осі Y — індекс кризи серед молоді (youth_mh_crisis_score).
Вхідні дані: Датафрейм з попереднього завдання.
Очікуваний результат: Побудований точковий графік.